I amar prestar aen, han mathon ne nen, han mathon ne chae, a han noston ned ‘wilith.
If you’re an avid conlanger, you might recognise the above as Sindarin Elvish. To everyone else, it’s simply Galadriel’s opening monologue from The Fellowship of the Ring.
Conlangs – that is, constructed languages – might seem like the exclusive domain of the fantasy and science fiction writer. However, the art of creating languages from scratch has been around for centuries and traces its origins back to religion and philosophy.
The Language Creation Society starts their conlang history timeline with Plato in 360 BCE; however, Merriam-Webster considers the first real conlang – though incomplete – to have been crafted by 12th Century catholic saint, Hildegard von Bingen, when she constructed Lingua Ignota for hymn lyrics using a new alphabet.
While early conlangs were philosophical in nature and not widely used (if at all), they did form the early foundations of an attempt to organise language and communication in a way that was perhaps more logical than their naturally occurring counterparts.
In the 19th century, the first practical conlang came onto the scene with the creation of Esperanto: an auxiliary language constructed with the intent to become a universal second language, promoting global communication.
While it didn’t take off quite as creator Ludwik Lejzer Zamenhof perhaps envisioned, it did become the world’s most widely spoken conlang, with some two million people speaking it today, up to 1,000 of whom know it as a first language.
Universal communication dreams aside, chances are you’re studying conlang creation because you’re a writer wanting to add some extra depth and authenticity to your speculative fiction world. There’s no shortage of conlang in science fiction and fantasy, and with conlang-laden pop culture juggernauts such as Star Wars and Game of Thrones, the appeal of SFF languages is at an all-time high.
(Did you know you can learn High Valyrian on Duolingo?)
But we’re not here to learn about other creators’ conlangs – we’re here to craft our own. Whether you’re a sci-fi writer wanting to expand your universe, a D&D dungeon master looking to add an extra layer of flair to your campaign, or a linguist up for a right ol’ challenge, check out our comprehensive step-by-step guide to creating your very own language.
Let’s start with the basics, shall we? A crash course in linguistics.

Step #1: Learn The Basics Of Language
If you want to create a language of your own, you need to know a little about how they work. No one expects you to go and enrol in a linguistics degree, though, which is why we’ve broken down some of the fundamental components into bite-sized info nuggets.
Linguistics, the study of language, comprises six main components:
- Phonetics: Speech sounds
- Phonology: Phonemes
- Morphology: Words
- Syntax: Phrases and sentences
- Semantics: Literal meaning of phrases and sentences
- Pragmatics: Meaning in context of discourse
While semantics and pragmatics are less likely to be required in any depth for a language used sparingly in literature or film, understanding the other four components will be fundamental in creating your conlang. Let’s look at these in more detail.
Phonetics and Phonology
Both of these concepts deal with the study of sounds, with phonetics focusing on individual speech sounds and phonology looking at phonemes, which are the sounds of speech used in a language. Basically, phonetics looks at all possible sounds, whereas phonology focusses on what phonemes occur in an individual language.
The number of phonemes in a language is not the same as the number of letters in the alphabet, which is used to express a written form. For example, the English language contains an alphabet of 26 characters, but has a phoneme catalogue of 44: 24 consonants and 20 vowels.
Compare this to Japanese, which has two ‘syllabaries’ consisting of 46 characters each, but only 15 consonants and 5 vowels, for a total of 20 phonemes.
In regards to creating your own conlang, you’ll primarily be working with phonology to determine what phonemes exist in your language; however, you’ll want a basic understanding of phonetics to understand what sounds are possible.
Morphology
Morphology is the study of morphemes – the smallest meaningful unit of language. We most easily recognise these as prefixes and suffixes, but they also include base words or ‘roots’, and can exist as entire words on their own. The latter are referred to as ‘free morphemes’, as they don’t require other components in order to have meaning.
Words such as ‘dog’ and ‘picture’ are considered free morphemes, as there is no further way to break them down; however, ‘dogs’ and ‘picturing’ are each compromised of two morphemes, being the base word (dog/picture) and the morpheme (-s/-ing) denoting the plural and present participle suffixes respectively.
Suffixes and prefixes are examples of ‘bound morphemes’ in that they cannot exist as a word on their own and must be attached to a root or base word in order to have meaning. Several bound morphemes can also be combined, such as in the word ‘unfortunately’, which is made up of the root ‘fortune’, prefix ‘un-‘, and suffixes ‘-ate’ and ‘-ly’.
The third method of categorising morphemes is whether or not they are inflectional or derivational. Inflectional morphemes are suffixes that primarily change the tense of a verb. These suffixes don’t change the meaning of the word, only its grammatical use, and therefore aren’t given a new listing in the dictionary. The plural ‘-s’ suffix is also an example of an inflectional morpheme.
Derivational morphemes are suffixes and prefixes added to roots to derive new words or change the meaning of the base word. For example, the free morpheme ‘kind’ can be transformed into the following: kindness (n.); unkind (adj.); kindly (adv.). The word ‘act’ can be changed into ‘react’, ‘enact’ and ‘actor‘, all of which have separate dictionary entries.
Building a master list of morphemes to understand how words are created and changed will streamline the creation of your lexicon (more on this later), and make it easier for learners of your conlang to deduce meanings of new and unknown words by identifying the logical pattern to their composition.
Syntax
The final linguistical component you’ll want to get your head around before diving into language creation is syntax. Syntax is a major component of a language’s grammar and describes the proper way to arrange words into clauses, phrases and sentences.
Syntax differs from language to language. English is an ‘SVO’ language: simple sentences are constructed in the order ‘subject’, ‘verb’ and ‘object’ (e.g. ‘I eat rice’). Other SVO languages include Spanish, Italian, Chinese and Swahili.
Korean, Japanese, Punjabi and Turkish differ slightly in that they are SOV (Subject, Object, Verb); in these languages, the above example sentence would be constructed as ‘I rice eat’. Languages can also follow VSO syntax, like Arabic, forming sentences that translate to ‘eat I rice.’
As clauses and phrases are added to make compound and complex sentences, further rules are added to govern where these additions are placed. Using our ‘I eat rice’ example, we know that modifications can be made by placing adverbs and adjectives before the verbs and nouns, and prepositional clauses at the end sentence can create the more detailed utterance, ‘I always eat delicious rice in the morning.’
How sentences are built from simple to compound/complex structures will depend on the base syntax pattern you use, so becoming familiar with how these patterns work in native languages will help create an authentic and practical foundation for constructing your own language.

Step #2: Understand How Sounds Are Made
Before jumping in and whipping up a whole bunch of phonemes for your conlang, it’s important to take the time to understand how sounds are made – and more importantly, how to convey this pronunciation to new speakers.
As we learned in Step #1, phonemes are the sounds that are occur in any given language and are classified as vowels or consonants, the number of which differ from language to language and do not necessarily follow a strict sound-to-symbol ratio. (Remember: English alphabet = 26, phonemes = 44.)
To further complicate this, regional dialects and variations impact the ways in which pronunciation is used and understood. For example, if you’re trying to teach someone that the first letter in your conlang’s alphabet is pronounced ‘a’ as in ‘tomato’, the result will differ depending on whether you (or your learner) is a speaker of American or Australian English.
To avoid confusion, and incorporate languages using entirely different writing systems, the International Phonetic Alphabet (IPA) was developed in the 19th century to represent an accurate and universal pronunciation guide to all languages. The IPA assigns a unique symbol to all phonemes that exist across all languages.
Type any word + definition into Google and you may notice a strange list of symbols underneath the word before its actual definition. For example, ‘dictionary’ is followed by /ˈdɪkʃ(ə)n(ə)ri/, which represents the word in IPA to help convey correct pronunciation to all speakers regardless of the pronunciation bias that may impact their instinctive interpretation of sounds.
The International Phonetic Association publishes an updated IPA chart to assist with interpreting this mish-mash of symbols. If you take one look at this chart and think, ‘What the heck is an epiglottal plosive???’, you’re most certainly not alone – so let’s break the chart down a little further to get to know the manner and places of articulation.
Manner of Articulation
This component of articulation describes how sounds are made in relation to the way in which air passes through our teeth, mouth and tongue from the lungs. This is represented on the IPA pulmonic consonant chart as the columns.
There are eight different manners of articulation. They are represented in the chart from top to bottom based on how open the airflow is, with the top of the chart being the most restricted, and the bottom the most open.
The vowel chart is a little harder to read, but follows the same basic principle: the manner of articulation is represented by the columns in descending order of openness.
Place of Articulation
As you might have guessed, the place of articulation relates to where the sounds are made within the human vocal apparatus. They are arranged on the IPA pulmonic consonant chart from left to right along the top as the location moves from the lips further down into the throat.
Unlike consonants, vowel formation is dependant on the position of the tongue inside the mouth and whether the lips are rounded or flat.
Moti Lieberman over at the Ling Space has some great videos regarding the manners and places of articulation of consonants and vowels relevant to a range of languages. If you want to learn more about articulation in regards to English so the source material is easier to get your head around, TOEFL educator Andrea Giordano has a great breakdown complete with videos and examples over on her website.
If your head is starting to spin from all this rudimentary linguistics, don’t worry – we’re nearly finished. There’s only one layer of foundation left to lay before we move onto the main event, and that’s asking yourself the following question: what kind of language do you need for your fictional world?
Step #3: Ground Your Language Within Your World
If you’re looking to create a conlang because you’re a writer of speculative fiction, chances are you’ve already done some pretty extensive world-building prior to this point. If not, that’s fine, but it might be time to dig a little deeper into your resource pools and start to identify the cultural and social structures within your world.
Defining the parameters of a language may seem like a hugely daunting task, but just as your fictional world was built by drawing upon real-life inspiration, your conlang can be derived in a similar manner.
Natural human languages are identified as belonging to several ‘families’, which are often depicted as and described using the metaphor of a tree. The Guardian published a series of illustrations by Mina Sundberg to demonstrate the relationship between languages, particularly the Indo-European – the most prolific and widely-spoken family of languages to which English belongs – and Uralic languages.
Looking at the similarities between the branches of each language family tree can be a great starting point for developing your conlang. For example, if your fantasy culture has drawn inspiration from Scandinavian roots, it stands to reason that the language may also bear similarities. After all, natural languages evolved from specific uses of a group of people at a point in time.
Of course, you’re dealing with a fantasy world here, so you may not want to draw too closely and borrow actual words or word roots. But you can make a solid start by using syntax, phonemes and morphology rules to build your own.
A time when relating heavily to a human language may be appropriate is if you’re working within science fiction. Say you have a group of characters with origins on Earth who have found their way to evolve on a new planet, for example. These ‘aliens’ may have once been Russian explorers (or refugees, or prisoners) who, during the centuries away from Earth, have grown to fit their new culture and surroundings. A conlang that is heavily immersed in the Slavic family, or even notably derivative of Russian, would be a fantastic, authentic touch to your world-building.
Other aspects to consider when developing a conlang that makes sense within your world is the physiology of the speakers. Remember that the sounds produced in any language are dependant on the manner and place or articulation, and be aware of how this may change depending on the physical makeup of your character’s vocal apparatus. If your speaker has an elongated snout and a forked tongue (or tongues!), you may need to take extra care to craft a conlang that makes sense to their physiology.
Stepping outside of the human vocal apparatus means you can probably throw a lot of the previously suggested rules out the window, but keep in mind that it will add an extra layer of difficulty when it comes to communicating this language to your readers. That said, if your world is full of wild and wonderful aliens, you may want to look at crafting a bridging language instead – one that humanoids are able to replicate and use.
Whether you’re dealing with space operas, high fantasy or contemporary fiction with a speculative twist, make sure you take the time to consider your language needs within the context of your story to ensure a clear, decisive direction when it’s time to great started.

Step #4: Fun With Phonemes
You’re here – you’ve done it!
After extensive groundwork and a rudimentary course in linguistics, you’re finally ready to get into the nitty-gritty of building a language from scratch. And there’s no better place to start than getting a feel for what your language is going to sound like.
The IPA chart may seem intimidating, but it’s the best way to organise and express the phonemes found in your conlang. If you’re having a tough time identifying the sounds due to the unfamiliar names and symbols, there are plenty of pronunciation guides available on YouTube, or you can check out this handy talking chart.
Once comfortable, you can get started by drawing up your own blank table and filling in the spaces applicable to your language.
Vowels
I’ve crafted the conlang ‘Kheshtarli’ – the language used by the people of Kheshtarl in my fantasy world – to assist with demonstration here. I decided to get started with determining my vowels, as these sounds form the nucleus around which syllables and in turn, words, are built (more on that soon!).
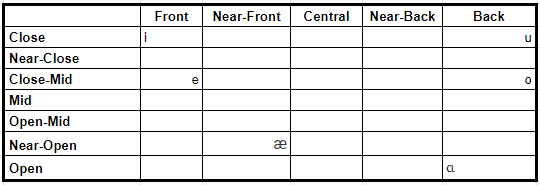
There are no rules surrounding how many vowels a language should include (aside from the fact that they must exist). However, all languages in use today contain at least three, which seem to be /i/, /a/ and /u/. Each of these three sounds are formed in three distinct places of the mouth, allowing for clear distinction between them. For Kheshtarli, I’ve identified six basic vowels out of the IPA’s 34 possible phonemes.
It’s worth noting that the European branches of the Indo-European language family tree tend to have a wider range of vowels at their disposal. Danish tops the list with a whopping 32 vowels. Other vowel-heavy European languages include Norwegian (19), French, German and Swedish (17).
English, for comparison has 12, while Greek, Russian, Serbo-Croatian, Castilian Spanish and the most widely-spoken conlang, Esperanto, have just five.
How many vowels you elect to use is ultimately up to you, but keeping it simple (or in line with your inspiration or personal mother tongue) will help you keep a hold on things, especially if this is your first conlang.
Consonants
The other chart you’ll need to complete is one for the consonants to help shape those vowels. If you’ve gone for a relatively small vowel base, don’t fall into the trap of thinking you need loads of consonants to balance things out, or vice versa.
Danish, with its healthy vowel base of 32, still has a wide range of 20 consonants; Japanese has 17 consonants to compliment its five vowels; and Lithuanian has a huge 47 consonants, bringing its full phoneme bank to a total of 77 sounds.
Just like with vowels, there are no hard or fast rules when it comes to deciding how many consonants to include, but unless you have a diverse vowel bank (like Danish), chances are your consonants will outweigh them in number, with the average inventory size considered to be around 22.
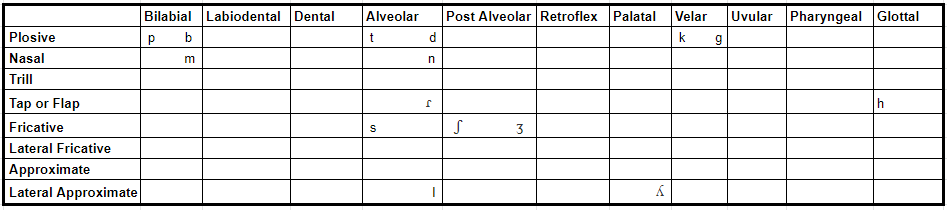
Kheshtarli consists of 15 consonants, which places it in the moderately small range, and gives me a total phoneme bank of 21 sounds to play with. To help keep things easy for me, I’ve elected to limit these to sounds I’m familiar with, and recommend other conlang first-timers do the same.
Syllables
Now you’ve determined the basic sounds to be found in your conlang, it’s time to think about how they come together into syllables. You probably recall learning about these units of speech by clapping along to words to determine their beats, but there’s a bit more to it than that.
Calling upon Oxford’s definition, a syllable is ‘a unit of pronunciation having one vowel sound, without or without surrounding consonants, forming the whole or part of a word’. If you think this sounds a little like a morpheme, you wouldn’t be wrong, but the main difference to remember is that morphemes relate to the meaningful structure of words, whereas syllables pertain to their pronunciation.
Syllables contain a nucleus, which consists of a vowel and two other components: the onset and the rhyme. The onset is any consonants that proceed the vowel, and the rhyme contains the nucleus (the vowel) and following consonants, also known as the coda. For example, the monosyllabic word ‘mat’ is structured consonant-vowel-consonant, or CVC.
In English, we can also have V syllables, such as /aI/ (‘eye’); CV syllables like /paI/ (‘pie’); or even greater clusters CCV, CCCV, CVCC or CVCCC. But this is not true of all languages. Hawaiian, for example, has some distinct rules regarding its syllables, in that they must never end with a consonant; are only one or two letters in length; and can be a single vowel, but never a single consonant.
My conlang, Kheshtarli, invokes similar limitations and contains only V, VC, CV and CVC syllables, with any vowels placed side-by-side becoming diphthongs and thus only considered one syllable.
Diphthongs
A diph-what?
This alien-sounding thing is actually the name given to the phenomenon of a noticeable vowel change within the same syllable. It may sound weird and wonderful, but diphthongs are quite common; in fact, the examples listed above, eye and pie, contain the diphthong /aI/, which sees the vowel sound ‘glide’ from an /a/ into an /I/ without pause, effectively maintaining the same beat and syllable.
Diphthongs are not always considered a part of a language’s basic phoneme bank and were actually counted separately in the breakdown listed above. They also do not occur in all languages; Danish, with its 32 vowels, contains no diphthongs, and neither do Hungarian or Polish.
Estonian, on the other hand, has a massive 28 diphthongs to compliment its base vowel bank of nine, with Romanian, Welsh and Finnish also having a penchant for the glide.
Diphthongs are also quite prevalent in English, with up to 13 in use across various regional accents. You can find a list of common diphthongs used in American English (with examples!) over at ThoughtCo to help get your head around these tricky things.

Step #5: Set Some Rules With Grammar
While grammar is generally understood to be the system and structure by which all languages are organised, it can actually be broken down into two additional components: syntax and morphology.
We mentioned these earlier, but just to refresh your memory, they refer to sentence structure and word structure respectively. When it comes to organising the delivery of your language, I find it easier to tackle the larger framework first, so let’s get stuck into syntax.
Your first step to laying your grammar rules is to decide what order subjects, objects and verbs fall in the basic sentence structure. We learned earlier that English is an SVO language (‘I eat rice’), but the SOV pattern is actually considered the most commonly occurring structure and thought to be the original rule from which languages evolved.
VSO languages are a distant third in commonality, with VOS, OVS, OSV being relatively rare.
Once you’ve decided your basic sentence structure, it’s time to make up some quick words from your phoneme bank to start putting these rules into practice. We’ll focus more on building our lexicon in the next step, so for now, just craft a handful of words (a pronoun, verb, noun, adjective, adverb etc.) that can be used to start playing with your syntax rules.
Kheshtarli is an SOV language, and for my practice sentence, I’m using the above example of ‘I eat rice’ to develop my syntax rules. As such, this would be translate to ‘nar eppae tolkhash’ in my conlang, with nar being ‘I’, eppae ‘rice’ and tolkhash ‘eat’.
English is a flexible language when it comes to building sentences, but that doesn’t mean there are no rules associated with its structure. The same should hold true for your conlang. There are four distinct patterns in English, and familiarising yourself with these can help you build your syntactic framework, especially in regards to conjunction use.
- Simple sentences: Single, independent clauses (like the example above: ‘I eat rice’)
- Compound sentences: Two or more independent clauses joined by a coordinating conjunction, including ‘but’, ‘or’, ‘and’, ‘so’ (‘I eat rice but I always spill it on the table’)
- Complex sentences: An independent clause combined with one or more dependent clauses (a subject + verb structure that does not express a complete thought), joined by a subordinating conjunction such as ‘although’, ‘because’, ‘so’, ‘that’, or ‘until’ (‘I eat rice but I always spill it on the table because I get distracted easily’)
- Compound-complex sentences: Multiple independent clauses as well as at least one dependent clause (‘When I eat rice, I try to be careful, but I always spill it on the table because I get distracted easily’)
Other rules we see in play here include the use of prepositions and descriptive modifiers (such as adjectives and adverbs). As adjectives describe nouns or pronouns, they are generally placed in close proximity to the object they’re modifying. In English, this happens before the noun (‘I eat delicious rice’), but can also come after and be separated by a verb (‘That rice is delicious‘).
Adverb placement is much the same; however, these modify verbs, adjectives or other adverbs. Many English adverbs are easily identifiable by the suffix ‘-ly’. We’ll talk about setting similar morphology rules below, but first, let’s talk about prepositions and how they factor into your conlang.
Prepositions comprise a group of words that are used before nouns, pronouns or a noun phrase to indicate direction, time, place, location, etc. Some quick examples include words such as ‘in’, ‘at’, ‘on’, ‘of’, and ‘to’. Learning correct usage in English can be difficult, as the rules are few and far between and generally dictated by fixed expressions. This certainly doesn’t need to be the case for your conlang.
In Kheshtarli, prepositions related to time, place or location will be stated at the beginning of the sentence, with the preposition placed after the noun. So, our basic ‘nar eppae tolkhash/I eat rice’ sentence would become ‘khara jol nar eppae tolkhash‘, with khara being ‘table’ and jol, ‘at’.
(You may notice that I have not translated the determiner ‘the’, as I’ve decided to not employ these rules in Kheshtarli. You don’t need to either, as languages generally don’t translate word-for-word.)
Before we move onto morphology, let’s put a compound sentence together using a conjunction, preposition and a couple of descriptors.
Khara jol nar umtak eppae shipta tolkhash-ret gal imda ishi kha.
‘At the table, I ate the delicious rice quickly because I have to go’.
New word bank:
- umtak = delicious
- shipta = quickly
- gal = because
- imda = must/have to
- (ishi) kha = (to) go
The sentence has now switched to past tense, as seen by our verb tolkhash becoming tolkhash-ret, which is the Khestharli equivalent to slapping ‘-ed’ on the end of a regular verb.
Now it’s time to start thinking about morphology in more detail, as we’ve started to deal with suffixes, which are common ways in which verbs are conjugated. While there are exceptions, we understand English verb tenses to change depending on which suffix is attached to the root – e.g. ‘jump’ becomes ‘jumped’ and ‘jumping’, for past and present continuous/gerund respectively.
Natural languages, however, are never straightforward. We know English also has verbs that conjugate irregularly, such as our example above: ‘eat’. The beauty of building a conlang is that exceptions don’t have to happen, which is the case with Kheshtarli. All verbs will become past tense by adding the suffix -ret, with no need to remember special cases.
By keeping your rules rigid and not faffing about with exceptions, you can quickly expand your lexicon by coming up with a bunch of suffixes and prefixes that can be tacked onto roots like linguistic Lego bricks.
At this stage of your conlang journey, you’ll probably want to get yourself a new notebook, because it’s time to expand that word bank to your heart’s content as we get stuck into your lexicon.

Step #6: Build Your Lexicon
If your head is swimming, don’t worry – we’re onto the fun part, I promise. Linguistic theory is behind us; our foundations are strong, and it’s finally time to tackle the most enjoyable (and easy) part of the conlang process: making up words!
If you’re only looking to use a conlang for a few sparse phrases featured throughout a larger piece of work, you can probably get away with just creating words willy-nilly; however, if you’re going the full hog and want a comprehensive language, you might want to consider a bit more structure when building your lexicon.
Side note: Both ‘lexicon’ and ‘vocabulary’ pertain to the words that make up a language, with the defining difference being that lexicon encapsulates word usage, function, classification and context. Vocabulary, on the other hand, refers to the segment of words used and understood by an individual, field of study, or social/cultural group.
For example, the vocabulary used by Gen Z is different to that of Baby Boomers; medical professionals understand words and phrases irrelevant to carpenters, and vice versa. Slang and dialects are considered part of the lexicon, but may not feature in the vocabulary of people outside of a specific time, place or group. In fact, the English lexicon contains about 600,000 words, but the average person only utilises around 2,000 in their vocabulary.
When it comes to building the lexicon for your conlang, you may be unsure where to begin. What do you need to include? What can you leave out? The answers to those questions will be specific to your own creation, but a good place to start is by breaking words down into parts of speech and deciding whether or not they are needed in your language.
Categorising your word bank using the eight parts of speech is a great way to get started with your conlang lexicon, as it breaks down the language into the types of words needed to form sentences. The parts of speech are as follows:
- Nouns: Words that name people, places, animals or things. Can be proper, common, concrete, abstract, countable, mass or collective
- Pronouns: Words that replace nouns
- Adjectives: Words that describe nouns or pronouns
- Verbs: Words that show actions or states of being. Sentences do not exist without verbs
- Adverbs: Words that describe adjectives, verbs or other adverbs
- Prepositions: Words that specify location, physical and in time
- Conjunctions: Words that join phrases, clauses or other words together
- Articles: Words that specify nouns (e.g. ‘a’/’the’; ‘this’/’that’)
As we discussed earlier, phonology and grammar will different from language to language. However, the parts of speech are universal. Many of these categories can be broken down further, with some having more variations in different languages.
English, for examples, has proper nouns, whereby names of countries, people and languages are signified by the use of initial capital letters; Japanese, on the other hand, has no such written distinction and instead indicates these with suffixes (-san for generic Mr/Ms; -go for a language; -ko for a lake).
Sometimes, it’s easy to recognise which part of speech words belong to by their sound or composition. For example, in English, adjectives ending in -ly are adverbs; in Japanese, if a word ends in -ru or -u, it’s probably a verb. These patterns can be an easy springboard for building more words and establishing conjugation rules for verbs, which are essential to functional languages.
Let’s review our Kheshtarli word bank:
- Nouns: khara/table; eppae/rice
- Pronoun: nar/I
- Adjectives umtak/delicious
- Verbs: tolkhash/eat; tolkhash–ret/ate; imda/must, have to; (ishi) kha/(to) go
- Adverb: shipta/quickly
- Prepositions: jol/at
- Conjunctions: gal/because
- Articles: N/A
There are two easily identifiable patterns in Kheshtarli: –ret for past tense and –ta as an equivalent for –ly in the creation of adverbs.
Through the experimentation of complex and compound sentences when ironing out our grammatical rules, we also created at least one word for seven of the eight parts of speech. Kheshtarli does not use articles in the same manner of English; while there will be words to indicate ‘this’ or ‘that’, specifying nouns with an equivalent of ‘a’ or ‘the’ is not necessary, so words of this category will largely be absent.
While there are no hard and fast rules regarding what words, or how many, you need to create for your lexicon, some useful words to consider are those that appear most frequently in your native language. ESL website, Go Natural English, has a comprehensive list of the top 1,000 most popular words in the English language, providing you with a healthy word bank to translate for your own lexicon.

Step #7: Craft A Writing System
Up until now, we’ve been putting a lot of work into what your language sounds like and how it comes together in communicable sentences. But what does it look like?
As English speakers, when we think of written language, we think of the alphabet – specifically the Roman alphabet, which is the writing system used by over 100 of the world’s languages, primarily throughout Western Europe. Considering there are over 7,000 languages on this planet, that does seem like a very small amount.
However, what you might find even more surprising is that the Roman alphabet is one of only eight alphabets currently in use. How can this possibly be the case?
Well, the alphabet is just one piece of the larger puzzle that is orthography, or the convention of writing a language including spelling, capitalisation and punctuation. Written language can utilise alphabets, adjads, abugidas, syllabaries or logograms to transcribe words and sounds.
Let’s look at each of these writing systems in more detail.
Alphabets
Alphabets are writing systems where sets of letters arranged in a fixed order create graphemes (symbols that represent phonemes) and encompasses both consonants and vowels.
Graphemes can be single letters or a combination of several, such as ch or ie. There can also be several ways to write the same phoneme – for example, the sound /ai/ can be expressed as ‘ai’, ‘a’ ‘-ae’ ‘a-e’ ‘-ay’ ‘ey’ ‘eigh’ ‘-ea’ or ‘-aigh’.
Other alphabets include Armenian, Cyrillic, Georgian, Greek, Hangeul (Korean), N’Ko and Tifinagh.
Adjads
The least common of writing systems, abjads contain graphemes that represent consonants only, leaving readers to their own devices when it comes to inferring vowel sounds. While these sounds may be indicated by diacritics (additional symbols and marks added to letters), this is not standard in these languages.
The most commonly occurring abjad is Arabic, but other examples include Hebrew and Thaana (the language of the Maldives).
Abugidas
Also known as ‘syllabic alphabets’, abugidas are writing systems consisting of symbols for both consonants and vowels, and are prolific throughout South and Southeast Asia.
In abugidas, phonemes (and their corresponding graphemes) are formed in a fundamental CV (consonant-vowel) syllable pattern, where the consonant symbol is modified by diacritics or other marks to indicate the vowel.
Of course, no language is as straightforward as only CV syllables (although, yours could be…), and so additional ‘zero consonant’ letters may be required for V syllables as well as modifications to allow for CVCC or CCV occurrences.
There are 22 abugidas in common use today, including Bengali, Burmese (Myanmar), Tamil, Thai and Tibetan. Kheshtarli, the conlang we’ve been using throughout this article, also falls within this category of writing systems.
Syllabaries
Building on the syllabic nature of abugidas are syllabaries, which are far more rigid than their mighty morphing cousins.
Syllabaries consist of graphemes representing CV or V syllables. These are considered phonetic writing systems, as the ‘letters’ always represent the same sound and are not modified or blended like abugidas or alphabets.
Japanese is by far the most widely known example of syllabaries, having two separate but similar systems: katakana and hiragana. Cherokee is another example of a syllabary, as is Yi, a language spoken by five million people throughout southern China.
Logograms
The final and most complex of writing systems in the logogram, or logograph, by which words are presented by symbols or pictures. Logograms are the earliest writing systems, with both Egyptian hieroglyphics and Sumerian cuneiform falling into this category; however, few are in use today.
Countries in East Asia, primarily China, Japan and Korea, still employ a logographic language, with written Chinese comprising solely of characters that represent whole words and morphemes. These sometimes complex characters can be divided up into radicles, or small recurring compounds/symbols that provide insight to their meaning and pronunciation.
Given the sheer volume of such a system (there are over 50,000 known Chinese characters, with 2,000 required for basic literacy), it would be considered very ambitious to attempt a logogram as the primary writing mode of your conlang.
If you’re set on the idea, or if it’s required for authenticity due to the real-world grounding of your language and culture, perhaps consider a hybrid system where only the most important ideas or words are represented as symbols.
Both the Japanese and Korean languages have adopted Chinese characters to varying extent, with the logograms used in conjunction with their own writing systems and modified to fit the local phonological patterns.
Once you’ve decided what form your orthography will take, you can set to work designing the symbols or letters. If you’re aiming for something outside the familiar (for us, something that’s not an alphabet!), head on over to Omniglot, the online encyclopedia of writing systems and languages, which contains scripts for languages both natural and constructed, including those that are extinct and undeciphered.
Of course, some languages are purely spoken, so depending on the needs of your conlang, you may be able to skip this step entirely. That leaves just one thing left to do: practice makes perfect!

Step #8: Start Practising
Before you start putting your conlang into use or rolling it out to the masses, it’s probably a good idea to spend some time with it yourself to get a working understanding of it on all levels.
As you play around with difference sentences and patterns, you will start to get a sense for what is working and what might need a review – the same as you would when revisiting a first draft with a trusty red pen.
Back in Step #5, where we started to lay some rules for grammar, we generated enough vocabulary to trial several difference sentences. This will serve as a great starting platform for our alpha test, especially in regards to verb conjugation, which may need a bit of tinkering to get right.
Let’s revisit our example conlang, Kheshtarli, to practise some new sentences and see if everything works smoothly.
Earlier, we learned that Kheshtarli verbs are conjugated with the suffix -ret to create past tense, and that there are no exceptions or irregular verbs. We also saw the infinitive form with the verb ishi kha/to go. Thus, ‘to eat’ is ishi tolkhash.
Using these rules, we can also conclude that kha-ret means ‘went’, being the past tense of ‘go’. All we need now is a present continuous (-ing in English) to complete our basic conjugation pool. Let’s make it ‘-lor‘.
- Nouns: khara/table; eppae/rice
- Pronoun: nar/I
- Adjectives: umtak/delicious
- Verbs: tolkhash/eat; tolkhash–ret/ate; imda/must, have to; (ishi) kha/(to) go
- Adverb: shipta/quickly
- Preposition: jol/at
- Conjunction: gal/because
- Article: N/A
Nar (umtak) eppae tolkhash-lor/I’m eating (delicious) rice.
Nar imda isha kha-ret/I had to go.
Nar shipta kha-lor/I’m going quickly.
One of the most important and versatile verbs you’ll need for your language is one that denotes existence, such as ‘am’/’is’/’are’ in English.
Just by playing around with the current words in our word bank, I was soon able to see how limited my sentences are without it. Building basic sentences is surefire way to discover any key words you may have overlooked when building your lexicon, as well as how it sounds when it all comes together.
Another part of language that you may discover you need at this stage of planning is punctuation. Even essential punctuation such as commas, full stops (periods), quotation marks and questions marks are not the same, or even present, in all languages.
Japanese, for example, does not utilise the question mark outside of informal, modern discourse (the internet, messages between friends, etc.), and instead announces interrogative statements by ending sentences with –ka. Their full stops are also tiny circles, and speech or quoted information is framed by「」rather than our curly “”.
If your conlang is being created for a fantasy world, using punctuation symbols from our world may not be applicable at all, but you may still discover that your require something to make your language more easily understood. A fundamental part of legible written English, for example, is sufficient spacing between words – something that doesn’t occur in Japanese or Chinese, but is necessary for understanding Korean.
Another thing to consider, especially if crafting a conlang using a script other than the English alphabet, is how it will expressed to learners or represented on page in your book.
As we’ve seen through this guide, Kheshtarli, when Romanised, requires spaces, but will feature no such convention in its written script. The hyphens that separate the word root from the verb conjugation will not be visual in Kheshtarli script, and additional punctuation will be required to indicate long vowel sounds, such as the ‘-tarl‘ in Kheshtarl.
The more you play around with your language, the more holes you are likely to uncover, so take the time to tinker and enjoy the process of learning (and creating!) something new.
That’s a lot of hard work… Can’t someone just do it for me?
If you’ve made it to the bottom of this guide and found yourself quoting that old favourite meme, ‘Ain’t nobody got time for that’, you’re certainly not alone. And that’s okay! As with everything, the internet is here to help.
Passionate conlangers (and likely ones who know how to code) have created several conlang generators to help fellow creatives add a level of authenticity to their project without the stress or hassle. Options include various degrees of customisation, free or paid packages, web browser–based or downloadable.
GenWord, GenGo and Awkwords are all examples of free conlang generators with simple interfaces. If you’ve already taken the time to create your phonemes and syllable structure, these are fantastic ways to rapidly build your lexicon with little brain strain on your end.
If you’re after something that will take you from whoa to go, Vulgar is a comprehensive yet simple fantasy language generator that ‘models the rules, irregularities of real languages: from grammar, to sounds, to vocabulary’. A free trial demo gives you up to 200 words complete with spelling and phonology, grammar, morphology guide and word bank – a great framework to get started, with plenty of space for your own modifications and growth.
For the ultimate conlanging experience, check out Polyglot: a free-to-use software made by conlangers for conlangers. Polyglot is extensive and includes lexicon, orthography, automatic word generation, grammar guide, consistency checker, and a spoken IPA guide, among many more features. With a detailed user guide available, it’s easy to see why this program is one of the go-to tools for serious conlangers.

Whether you’re looking to create a language to add depth and authenticity to your novel or tabletop gaming campaign, or simply looking for an imaginative new hobby, the art of conlanging is supported by a global, passionate community.
This rewarding endeavour may be just what you need to elevate your project to new heights – and one day you might even find it taught on Duolingo!
Already started a conlang? Tell us about your journey in the comments below.
Taelor!
(Kheshtarli for farewell)